

In time-series databases, the operation of resources is a complex and crucial task. These operations often involve multiple steps, each of which may fail, leading to an inconsistent state of resources. For example, a user might want to delete a tenant in a CnosDB cluster, an operation that may require the deletion of various resources under the tenant (such as role, database, member, etc.). If any step in this process fails, the operation could leave the cluster in an inconsistent state. To address this issue, we have designed a solution.
Based on this goal, we referred to some well-designed products.
Solution Reference: HBase's ProcedureV2 (Pv2) Framework
In HBase, a Procedure represents one or a set of operations, divided into the following states:
– INITIALIZING – Procedure under construction, not yet committed for execution
– RUNNABLE – Procedure committed and ready to execute
– WAITING – Procedure waiting for completion of a child Procedure
– WAITING_TIMEOUT – Procedure waiting timeout or event interruption
– ROLLEDBACK – If a Procedure or its child Procedure fails, it will roll back, cleaning up resources created during execution. Rollback may occur multiple times in failure or restart scenarios, hence rollback steps must ensure idempotence
– SUCCESS – Procedure successfully completed without failures
– FAILED – Procedure executed at least once and failed, either rolled back or not yet rolled back. Any Procedure in a failed state will switch to rollback status
By clearly dividing and recording each step of a Procedure, atomicity and consistency of multi-step execution are achieved.
Final Solution: ResourceManager
Based on CnosDB's situation, we introduced the ResourceManager function.
ResourceManager can retry failed tasks in the background until the operation succeeds. Thus, even if a step fails, ResourceManager can ensure final consistency. For example, in the tenant deletion operation mentioned above, if the step of deleting a database fails, we can create an asynchronous task to retry this step and subsequent steps. This asynchronous task runs in the background and will keep retrying until successful. In this way, we ensure that even in the face of failure, our system remains consistent.
ResourceManager also supports delayed tasks, allowing tasks to be preset with an execution time. When the time arrives, the task will be executed and retried in case of failure.
In summary, ResourceManager provides a powerful and flexible way to handle multi-step task operations in time-series databases, ensuring the final consistency of the system.
Task Status Classification
Tasks are classified into different states based on their situation:
– Schedule – Task submitted to ResourceManager, not yet executed
– Executing – Task currently being executed
– Succeeded – Task successfully completed
– Failed – Task failed, will be retried
– Cancel – Task not executed, canceled
– Fatal – Task encountered an unrecoverable error during execution, will not be retried
Task Status Viewing
To clearly understand the current execution status of tasks, a system table `resource_status` is provided, which can be viewed with the command:
`SELECT * FROM information_schema.resource_status;`
The table includes:
| time | name | action | try_count | status | comment |
| 2023-11-03 05:47:28 | cnosdb-db1 | DropDatabase | 1 | Successed |
Specific Scenarios
Scenario One
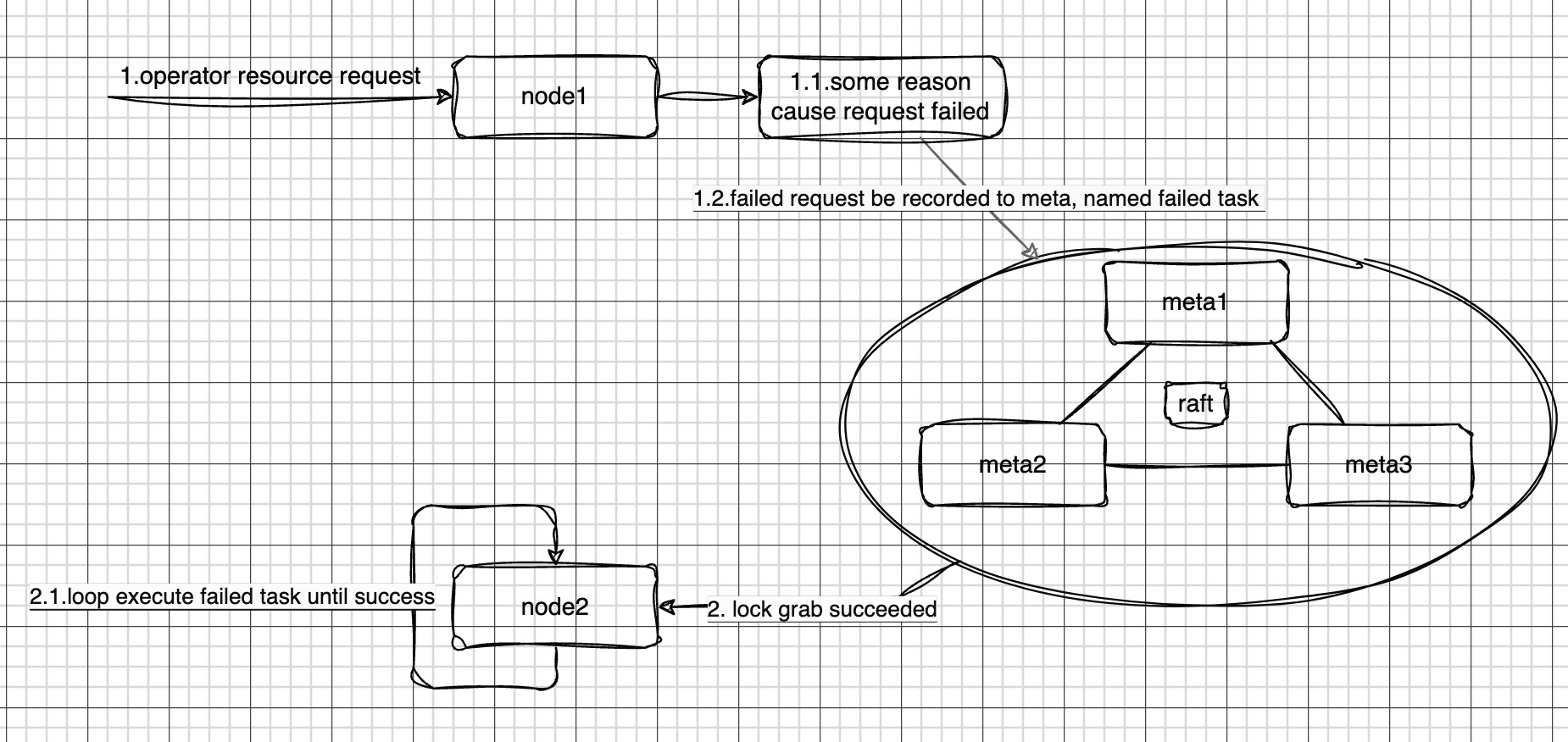
In a CnosDB cluster, resource operation requests may be sent to any node for processing. For example, a request might be sent to a node named node1. However, due to network latency, hardware failures, or other reasons, this request might fail. When node1 encounters a failure in processing the request, it not only returns an error but also records this request as a failed task in meta.
In the CnosDB cluster, multiple nodes (such as node1, node2) periodically read failed tasks from meta. To prevent multiple nodes from retrying the same task, only one node can successfully read the task. In our hypothesis, node2 successfully reads this task.
Once node2 retrieves the failed task, it begins to cyclically retry the task until successful, recording the error information of failed executions. This design ensures that our system can ultimately complete all requests even in the face of failure.
Operations currently supported for failure retry include:
DropTenant, DropDatabase, DropTable, DropColumn, AddColumn, AlterColumn, RenameTagName, UpdateTagValue.
Scenario Two
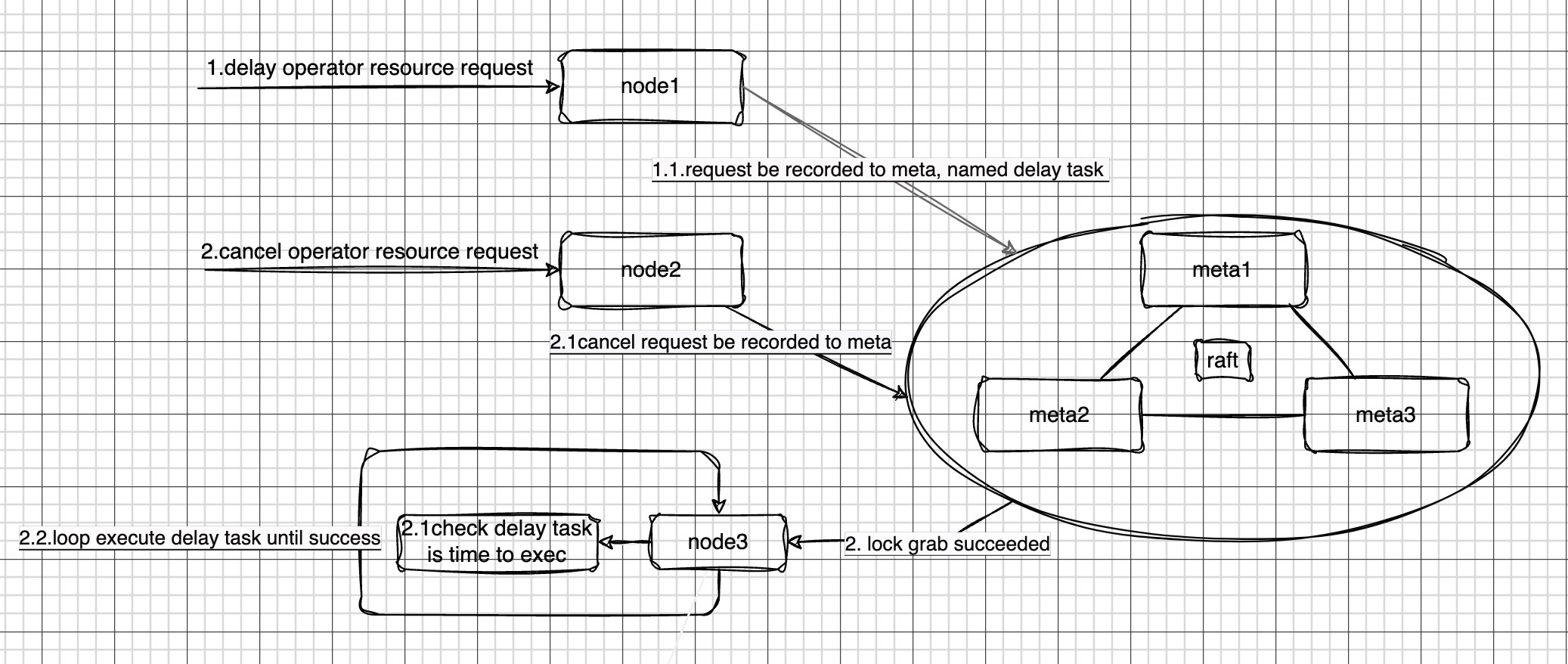
In the CnosDB cluster, when node1 receives a delayed task, it is recorded in meta. Meta has a data structure for storing task information, which can be accessed and read by all nodes in the system.
Multiple nodes (such as node1, node2, node3, etc.) will attempt to read the task list from meta. However, to ensure the consistency and correctness of tasks, the system has designed a lock mechanism that allows only one node among many to successfully read the task list. In this example, we assume node3 is the node that successfully reads the task.
Once node3 successfully reads the task list from meta, it begins to process the tasks. First, it checks whether the current time has reached the scheduled execution time of the task. If the scheduled time has not yet been reached, node3 will skip that task; if it has reached the scheduled time, node3 will begin executing the task.
During the execution of the task, node3 adopts a cyclical execution strategy. That is, if the task is not successful on the first attempt, node3 will try to execute it again until it is successful. Additionally, to ensure the reliability and traceability of the system, node3 records the current execution status and results in the system table each time a task is executed. The execution status of tasks can be viewed by checking the system table.
Another scenario is if the request to cancel the delayed task is issued to node2 before node3 successfully reads it. This request will be recorded in meta, and the delayed task will not be executed when the preset time arrives.
Through the above design and implementation, the system can effectively and correctly handle delayed tasks and can track and record the execution status and results of tasks in real time.
Operations currently supported for delayed tasks include: DropTenant, DropDatabase.